It’s coming they say. Not winter (that’s here already), but mobile 5G is coming. Sure the latency will allow a new generation of mobility applications. The new RF control functions will allow better elasticity. The network slicing will finally allow MPLS-like functionality in a 3GPP network. But I think its time someone asked the basic questions on how 5G will impact operations.

Basic Tutorial and Terminology
5G means different things to different people. The money involve means industry will be providing competing visions. The essence of 5G is focusing on improving latency, bandwidth, network slicing, and elasticity. Adding more endpoint (antennas) and distributed control functions will reduce the latency. The control functions permitted more distributed switching. The extra endpoints means fewer network mileage required. These latency benefits are the biggest game changer so far.
The simplified control functions also enable better elasticity options. Scaling up/down/in/out will allow a more natural self-optimizing network. Adding class-of-service capabilities (like QoS in MPLS) will allowed tiered network options. While net-neutrality questions still loom, this adds diversity to the single-use mobile network. The amount of network required is still to be defined, but it looks to be at least 10x. Mobile operators are also taking this opportune time to diversify their vendors. Most US providers are adopting radios from at least two vendors.
The bottom line for operations is potentially terrifying. Exponential scale in the network and backhaul is to be expected. Exponential complexity increase with a “always in flux” network. New network offerings and customer bases are bound to cause trouble. Top those off with at least doubling the vendors. Houston we have a problem!
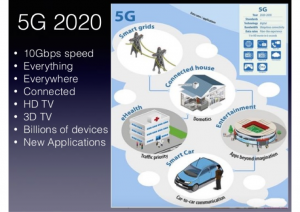
Next-generation Mobile Network Services
As you can see, the investment will be significant. The upside should be worth it though. Traditional mobile services are commoditized as I blogged here last year. Data, voice, and SMS do not provide enough value to the customer. The new services provided will change that. With the latency benefits, IoT services will become more viable. I detailed IoT more in the previous blog around IoT Service Assurance. In my opinion, the most intriguing new offering is “fixed wireless access” (FWA). Ericsson did a really nice write up available here. Verizon is augmenting their FIOS offer with a FWA offer in 2018. This means that mobile providers are entering into the cable access market (HFC). This sets Verizon against Comcast or T-mobile against Charter. Gone will be the days that we will locked into high speed internet options solely by developed the neighborhood.
These new network services will drive new revenue potentials. Most of these services will have direct competition so quality will matter. With all these changes operations should expect challenges. We should all expected quality problems with these new services.

Exponential Scale and Complexity
The first great challenge will be scale and complexity. Tripling the number of devices in your network will stress your tools. Realistically, can your OSS handle a 10x-1,000x increase in network size? But this is not the only issue. The self-optimizing vRAN means that network will constantly be in flux. How can you troubleshoot a network that is always changing? Due to size of investment, it only makes sense multiple vendors will be used. Most mobile operators heavily depend upon their NEPs to provide OSS solutions.
The solution is simple, in fact simplification. A vendor, technology, and product agnostic OSS solution is a must. As you increase your tools, the complexity limits functionality. Low-level optimization and orchestration can be done at the element manager layer. This increases scale of both layers of the solution.
Becoming Geospatial Again
Remember the HP OpenView days of maps? When get prepared for those concepts to return. Like wifi antennas, 5G deploys radios with geospatial design in mind. Geospatial information (Lat/Long) will then drive behavior. GIS Correlation and visualization then becomes a need. Correlation and analytics are vital to reducing the complexity of 5G vRAN networks. External network conditions becomes more indicative. Things like hurricanes, floods, and power outages need to be taken into account. This is very similar the cable industry (HFC) access monitoring requirements. Operations will need help because most legacy tools are inadequate in these areas.
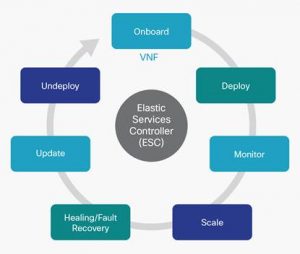
Bending but not Breaking with Elasticity
Elastic scaling the network is not a 5G concept. The trouble is we have seen that many, if not most, of the network functions are beats. Components like MMEs and SGWs take hours to spin up and configure. This reduces the value of elasticity in 3GPP networks. 5G replaces many complex functions, like eNodeBs, with smaller control functions. This will enable all the promises of network virtualization. The question becomes does operations have orchestration tools to enable automation. Some NEPs are building those functions into the element managers or VNFMs. Most service assurance tools do not have the capability to handle the network flux called by real-time elasticity. Operations will need to review their tools to make sure they are agile enough.

Operations Face Uphill Battle
The industry is beating the drums, 5G is coming. But I do not hear from the industry how operations will consume it. From my experience, nobody knows. Legacy tools are too difficult to share information. They are too tied to a vendor or technology domain. Most tools have difficulty scaling to 100k-5m devices. This forces most customers to silo their monitoring and management. This creates lacking visibility capability with drives quality issues. Most operational processes are ticket or fault-centric. Correlation is lagging behind. There will be too many faults to process. Visualization of the network will be a critical need, but may not be possible. Like winter, 5G is coming, so where is my 700 ft wall?

About the Author
Serial entrepreneur and operations subject matter expert who likes to help customers and partners achieve solutions that solve critical problems. Experience in traditional telecom, ITIL enterprise, global manage service providers, and datacenter hosting providers. Expertise in optical DWDM, MPLS networks, MEF Ethernet, COTS applications, custom applications, SDDC virtualized, and SDN/NFV virtualized infrastructure. Based out of Dallas, Texas US area and currently working for one of his founded companies – Monolith Software.