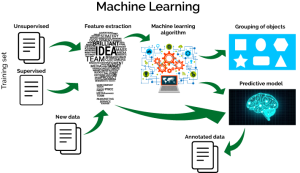
Now let us discuss the challenges addressed by machine learning with AI. As we learned in the previous blog, machine learning is excellent in model building. These operational models enable leveraging historical data. Artificial Intelligence is great at doing comparisons to produce results. Identifying anomalies and chronic with ease lowers effort requirements. So how does this help us? Lost plot by many, operations have discrete problems. Technology is only valuable if applied to problem areas. Here are some the common discussed areas I have seen in the marketplace — names withheld.
Normalizing Faults

One common problem is the normalization of fault data. For example, SNMP traps are a very common fault format and protocol. Its binary format of enterprise and integer indicating a trap number. This requires human beings create database lookups (called MIBs) to provide descriptive detail of the fault. This discounts operational configurations like Up/Down correlation or aging configuration settings. Learning these configurations is a possible area for using machine learning technology. AI can compare common worded, complete configured trap types and guess what they should be. Human beings can right-click, update where applicable. The result would be a build-as-you-go rules engine curated on-the-fly. Many Managed Service Providers (MSP) find this interesting. Any organization with diverse and changing data set would find it valuable.
Correlating Faults

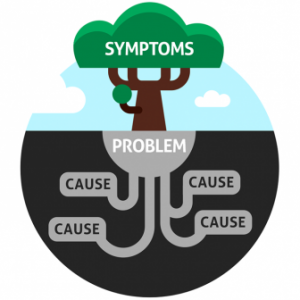
Correlation is another concern. Operations need efficient ways to identify, isolate, and act on situations. They do not have time to discern association. As discussed, machine learning can identify a model of what is normal. The same model enabling the anomaly enables a set of context, which allows for reverse correlation. The allows anomalies to drive encapsulation of the situation.
Now looking forward, machine learning with AI can identify if this has happened before – or chronic detection. This opens the door to closing out chronic situations. Imagine a burst outage. Operations sees a failed service that clears – down, then back up. Most people end up ignoring these errors. The reason is that a final resolution is impossible to achieve. Unfortunately its uncommon to track them. If they re-occur, tools need to identify that they are not “blips” they are chronic. Long-term, the goal is to forecast them. That way preparations can occur to capture key data. The goal will be to engage to get final resolution of the chronic and prevent their repetition. With machine learning with AI, chronic detect and mitigation becomes possible — which we will discuss in more detail later.
Prioritizing Faults

Another problem for operations is data overload. While a problem may be a root cause and an individualized “situation”, operations may not CARE. If a customer takes down their service, operations must make the logical choice to IGNORE a situation. Leaving this up to humans introduces human error. With machine learning you can understand that this problem common and should be identified as a chronic situation. This enrichment allows operations to re-prioritize new situations over chronic situations. This allows a more accurate report of what is going on with an operational priority assigned.
Operations also have a problem with reporting. Post-mortem analysis can encumber operations available to learn from failures. In a matter of minutes, machine learning with AI technology can scan years of raw data to see a the particular pattern. That pattern can segment what affect a situation had on the network. The bottom line is operations can report on the what, why, where, and how using machine learning with AI technologies.
Article Map
- My Journey into Machine Learning with AI
- The Technology of Machine Learning with AI
- Challenges Addressed by Machine Learning with AI
- An Umbrella for Fault Storm Management
- Minimizing Faults with Machine Learning and AI
- Learning Your Operational Performance
- Automated Detection & Mitigation of Chronic Issues
- Service Assurance’s Future with Machine Learning
- End of the Beginning for Machine Learning

About the Author
Serial entrepreneur and operations subject matter expert who likes to help customers and partners achieve solutions that solve critical problems. Experience in traditional telecom, ITIL enterprise, global manage service providers, and datacenter hosting providers. Expertise in optical DWDM, MPLS networks, MEF Ethernet, COTS applications, custom applications, SDDC virtualized, and SDN/NFV virtualized infrastructure. Based out of Dallas, Texas US area and currently working for one of his founded companies – Monolith Software.